TSQL原理
# 1. 执行计划
TSQL对于使用者而言在关联模型处理上是一个黑盒,对于关联模型级联查询还是关联模型where条件,使用者很难想象真实的物理SQL是什么样子,因此我们提供了TSQL执行计划,输入待执行TSQL就可以获取对应的物理SQL树。
1.1 使用方式
暂时没有在交付控制台提供界面,先通过调用DS内部接口
curl
curl -X POST \ 'http://127.0.0.1:8080/api/data/sql/explain?projectId=trantor_gaia_test' \ -H 'Content-Type: application/json' \ -H 'cache-control: no-cache' \ -d 'select *,relationEntity.* from organization_EmployeeBO where user.id = 6001'path,将IP和projectId替换成对应环境的ds ip以及DS_PROJECT_ID
http://127.0.0.1:8080/api/data/sql/explain?projectId=trantor_gaia_testrequest body就是sql,如果是预编译形式的SQL,可以不传params或者把params拼接到原始sql上
select *,relationEntity.* from organization_EmployeeBO where user.id = 6001结果是一个物理SQL树
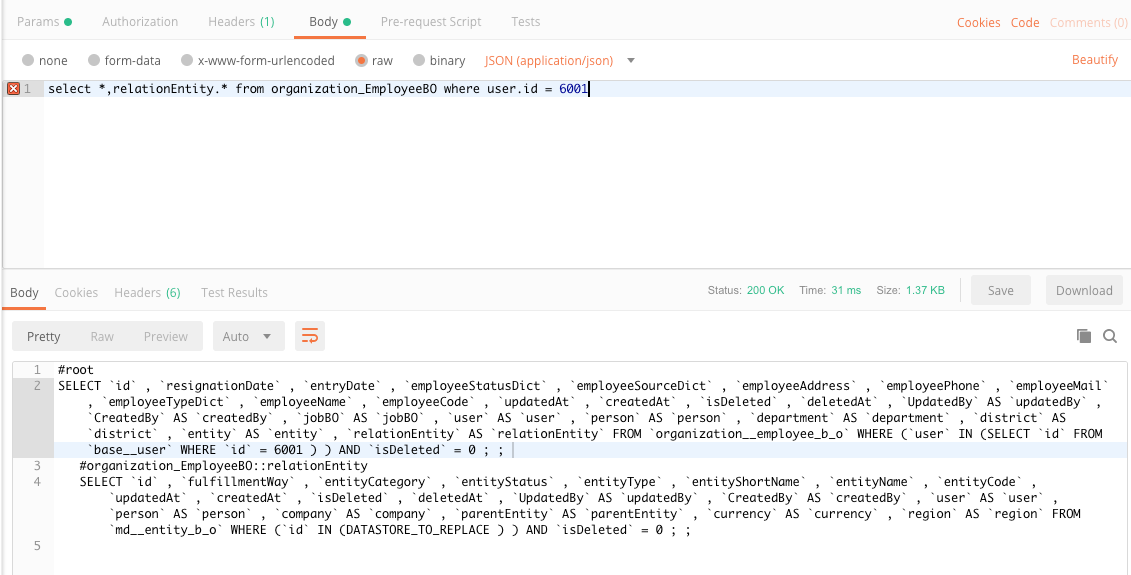
1.2 理解执行计划
原始TSQL
select *,relationEntity.* from organization_EmployeeBO where user.id = 6001执行计划
#rootSELECT `id` , `resignationDate` , `entryDate` , `employeeStatusDict` , `employeeSourceDict` , `employeeAddress` , `employeePhone` , `employeeMail` , `employeeTypeDict` , `employeeName` , `employeeCode` , `updatedAt` , `createdAt` , `isDeleted` , `deletedAt` , `UpdatedBy` AS `updatedBy` , `CreatedBy` AS `createdBy` , `jobBO` AS `jobBO` , `user` AS `user` , `person` AS `person` , `department` AS `department` , `district` AS `district` , `entity` AS `entity` , `relationEntity` AS `relationEntity` FROM `organization__employee_b_o` WHERE (`user` IN (SELECT `id` FROM `base__user` WHERE `id` = 6001 ) ) AND `isDeleted` = 0 ; ; #organization_EmployeeBO::relationEntity SELECT `id` , `fulfillmentWay` , `entityCategory` , `entityStatus` , `entityType` , `entityShortName` , `entityName` , `entityCode` , `updatedAt` , `createdAt` , `isDeleted` , `deletedAt` , `UpdatedBy` AS `updatedBy` , `CreatedBy` AS `createdBy` , `user` AS `user` , `person` AS `person` , `company` AS `company` , `parentEntity` AS `parentEntity` , `currency` AS `currency` , `region` AS `region` FROM `md__entity_b_o` WHERE (`id` IN (DATASTORE_TO_REPLACE ) ) AND `isDeleted` = 0 ; ;对于这个TSQL,核心的点就是select分支上的relationEntity.xxx和where分支上的user.id = 6001
user.id = 6001 这个分支将会被解析成主模型查询上一个in查询
这里之所以不直接用user=6001,而是要转换成关联模型上的一个in查询,是因为我们需要确保关联的记录存在 考虑一种场景,假如这里直接用user=6001,根据where条件可以查询出数据,但是通过查询出的employee_b_o去搜索关联的user记录时有可能发现user记录不存在,这种情况就相当于employee_b_o上的user是一条脏数据
relationEntity.xxx将会被单独解析成一条sql,对应#organization_EmployeeBO::relationEntity这个分支,这个sql上有一个DATASTORE_TO_REPLACE的占位符,之所以要有这个占位符是因为树的子节点执行依赖父节点的结果集,因此当父SQL未执行时,子SQL是拿不到依赖的数据的,但是我们需要在解析阶段把所有物理SQL都生成出来,因此需要一个特殊的占位符拼接到物理SQL中,当真正执行时DS会根据上下文从父SQL结果中获取依赖的数据注入子SQL中
2. 原理
TSQL的核心流程为
语法解析 -> 语义分析 -> 元信息绑定 -> 生成物理SQL -> 执行物理SQL -> 组装结果
在生产物理SQL这一步,会将所有可能需要执行的物理SQL都生成出来,这里之所以用可能这个形容词是因为在多级模型查询时,取决于上一级模型的查询结果,有可能不需要去查询下一级的模型数据。
下面用四个模型来描述整个流程
供应商(Partner)、供应商身份(PartnerIdentity)、银行(Bank)、用户(User)
一个供应商对应一个供应商身份,一个供应商身份对应多个银行信息,所有的模型都会有一个创建人(对应User模型)
核心字段:
- Partner中有一个partnerIdentify关联字段,关联到PartnerIdentity模型。
- PartnerIdentity中有一个banks字段,关联到Bank模型
- 所有模型都有一个createdBy字段,关联到User模型
2.1 单模型查询
select `id`,`name`from `partner_center_Partner`where `code` = 'CO2020122800001';以这个输入为例,查询code值为CO2020122800001的id和name
经过解析阶段,将会生成下面的物理sql
SELECT `id` , `name`FROM `partner_center__partner`WHERE `code` = 'CO2020122800001' AND `isDeleted` = 0 ;对于单模型查询,DS做的事情大致包含下面这些事情
- 根据元信息替换输入的字段名、表名、关键字
- 如果模型是逻辑删除的,增加isDeleted = 0这个条件分支
- 如果字段声明了dbName(表中物理字段名),添加别名
2.2 多级模型查询
2.2.1 两级模型
关联模型的流程与单模型查询相比,多了一步操作,就是根据关联关系,生成子查询语句
select`id`,`name`,`code`,`partnerIdentify`.*from `partner_center_Partner`where code = 'AAA';上面这个查询去查询code为AAA的供应商的name和code,同时查询这个partner关联的所有partnerIdentify的数据
所以很容易就能想到一个点,就是当code=AAA的partner id不存在时,不需要查询关联的partnerIdentify的数据
只有当主模型记录存在,才会根据主模型查询结果去查询子模型记录
但是我们在解析时也需要生成这个子模型的查询SQL,因此一定需要某种特殊标识来标识这种行为。
生成的物理sql为下面两条
SELECT `id` , `name` , `code` , `PartnerIdentifyPartner` AS `partnerIdentify`FROM `partner_center__partner`WHERE `code` = 'AAA' AND `isDeleted` = 0 ;这一条为主模型的查询sql
SELECT `taxpayerLevel` , `isInternalSupplier` , `cleanAccountProveSignTaskBillCode` , `payType` , `businessBeginAt` , `id` , `fax` , `registerCode` , `useElectronicSignature` , `authorizer` , `registerFund` , `healthLicenseCode` , `isThreeCertToOne` , `isPurchaserAndSupplier` , `sourceType` , `purchaseGroup` , `shortName` , `returnGoodAuthorizerCardId` , `itemCategory` , `legalRepresentativeName` , `businessLicenseCode` , `authorizerCardId` , `registerType` , `authorizerContact` , `isDeleted` , `businessLicenseRegisterAddress` , `email` , `payCondition` , `website` , `registeredCaptical` , `address` , `inSaveStatus` , `businessStatus` , `solutionGroup` , `unifiedCocialCreditCode` , `settleType` , `country` , `legalRepresentativeId` , `credentialsType` , `registerSource` , `createdAt` , `nameUsedBefore` , `businessEndAt` , `taxpayerType` , `payMethod` , `invoiceType` , `legalRepresentativeContact` , `foundAt` , `groupCode` , `updatedAt` , `companyCode` , `cooperateStatusChangeTime` , `outCode` , `postcode` , `businessScope` , `businessTerm` , `deletedAt` , `purchaseScope` , `name` , `idCardAddress` , `supplierType` , `timeToMarket` , `note` , `onlineCooperateType` , `paymentFund` , `code` , `credentials` , `returnGoodAuthorizer` , `purchaseType` , `cooperateStatus` , `packageLevel` , `parentCode` , `financeEmail` , `supplierGroup` , `accountGroup` , `enterType` , `allocationType` , `enterpriseType` , `authorizerDept` , `longTermEffective` , `authorizedAgencyNo` , `cleanAccountProve` , `taxpayerCode` , `updatedBy` AS `updatedBy` , `createdBy` AS `createdBy`FROM `partner_center__partner_identify`WHERE `id` IN (DATASTORE_TO_REPLACE ) AND `isDeleted` = 0 ; ;这一条为查询子模型的sql,可以看到原始输入的*被替换成了这个模型的所有真实字段名,关键点在where条件
`id` IN (DATASTORE_TO_REPLACE )DATASTORE_TO_REPLACE就是一个占位符,当第一个sql查询出结果后,需要将第二条sql依赖的值替换成真实的查询结果,比如主模型查询结果PartnerIdentifyPartner = 1,则DATASTORE_TO_REPLACE将会在执行时被替换成1。
2.2.2 多级模型
下面再举一个复杂的多级模型例子
select`id`,`name`,`partnerIdentify`.`id`,`partnerIdentify`.`banks`.`id`,`partnerIdentify`.`banks`.`bankType`,`partnerIdentify`.`createdBy`.`nickname`from `partner_center_Partner`;where `code` = 'AAA'这条sql查询了partner模型的id、name,以及关联的partnerIdentify的id,以及partnerIdentify关联的banks,以及partnerIdentify关联的createdBy的nickname。
这条sql我们可以映射到下面这个树结构,level 0对应主模型查询(父模型),level 1对应主模型的一级关联子模型查询(子模型),level 2对应子模型的下一级关联模型(孙模型)
partner -> level 0 partnerIdentify -> level 1 banks -> level 2 createdBy -> level 2生成的sql
level 0:根据输入的条件查询主模型数据,这里的PartnerIdentifyPartner是关联字段名(因为要获取下一级模型的id)
SELECT `id` AS `id` , `name` AS `name` , `PartnerIdentifyPartner`FROM `partner_center__partner` ;WHERE `code` = 'AAA' AND `isDeleted` = 0 ; ;level 1:查询partnerIdentify这个子模型数据,DATASTORE_TO_REPLACE的值就是上面的level 0查询结果中的PartnerIdentifyPartner值。
SELECT `id` AS `id` , `CreatedBy`FROM `partner_center__partner_identify`WHERE id IN (DATASTORE_TO_REPLACE ) ;level 2:查询partnerIdentify关联的banks,这里的DATASTORE_TO_REPLACE值就是level 1中查询结果的id值,因为关联字段建立在Bank模型上(一对多),所以这里需要根据主模型id到子表中查询
SELECT `bankType` AS `bankType` , `id` AS `id`FROM `partner_center__bank`WHERE PartnerIdentifyBank IN (DATASTORE_TO_REPLACE ) ;level 2:查询partnerIdentify关联的createdBy,这里的DATASTORE_TO_REPLACE值就是level 1中查询结果的CreatedBy值,因为关联字段建立在PartnerIdentity模型上(一对一),所以这里需要根据主模型关联字段值到子表中查询
SELECT `nickname` AS `nickname` , `id` AS `id`FROM `base__user`WHERE id IN (DATASTORE_TO_REPLACE ) ;当level 0查询不到数据时,level 1的DATASTORE_TO_REPLACE实际上没有值可以替换,因此只有当上一级存在查询结果时,才需要执行下一级查询。
复杂的点在于上下级sql的依赖关系,因此需要一个上下文对象,里面存放的是每一级查询sql所依赖的父sql中的查询结果,因为子模型查询中的DATASTORE_TO_REPLACE这个占位符,需要知道到父模型查询结果中取哪个字段值。
2.3 原生Join/子查询
对于MySQL原生Join和子查询语法,DS的处理流程跟单模型查询没有区别,只是替换表名和字段名,添加删除策略条件分支,不再赘述。
2.4 聚合函数
聚合函数上稍微特殊一点
输入
select max(`id`),min(`id`)from `partner_center_Partner`;对于函数查询,物理SQL将会与输入存在一定差异
SELECT MAX(`id` ) , MIN(`id` )FROM `partner_center__partner`WHERE `isDeleted` = 0 ; ;可以看到物理SQL中输入的max(`id`)变成了MAX(`id` ),所以不能直接从Response中get max(`id`)这个key获取数据,目前建议通过添加别名来解决重写后不一致。
建议的输入
select max(`id`) as maxId ,min(`id`) as minIdfrom `partner_center_Partner`;输出
SELECT MAX(`id` ) AS `maxId` , MIN(`id` ) AS `minId`FROM `partner_center__partner`WHERE `isDeleted` = 0 ; ;2.5 结果集解析
根据字段定义的类型,在查询出数据库结果后可能需要进行类型转换
- Boolean类型:存储到数据库是tinyint/number,查询出结果后需要转成boolean值返回
- Json类型:存储到数据库是mediumtext/CLOB,查询出结果后需要转成JSON返回(JSON.parse(fieldDBValue.toString()))
- DateTime类型:存储到数据库是datetime/DATE,查询出结果后需要转成java的Date类型通过getTime()返回long类型值(((Date) fieldDBValue).getTime())
- Time类型:存储到数据库是time/CHAR,查询出结果后需要toString返回
- Int类型:存储到数据库是int/number,查询出结果后需要转成Integer返回
- Long类型:存储到数据库是bigint/number,查询出结果后需要转成Long返回
- 创建人(createdBy)/修改人(updatedBy):查询出结果需要转成Map结构,Map中key为id,值为查询结果