DS 水平分表功能概述
当某张表的数据超过一定数量后,会严重影响查询速度,影响程序性能,一般做法设置一个分表键,将一张表拆分成多张表,所以DS提供了水平分表功能, 通过简单的配置,即可使用水平分表功能。下面进行介绍。
1.DS 水平分表是怎么做的?模型水平分表后有什么限制?
DS内部基于Apache Sharding-JDBC实现,目前DS基于官方版本4.0.0-RC2维护了自己的一个分支,修复了相关bug,增强了相关功能。 Apache Sharding-JDBC官方网站:https://shardingsphere.apache.org/
模型开启水平分表后,相对于单表,存在以下限制:
| 不支持的SQL | 不支持原因 |
|---|---|
| INSERT INTO tbl_name (col1, col2, …) VALUES(1+2, ?, …) | VALUES语句不支持运算表达式 |
| INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ? | INSERT .. SELECT |
| SELECT COUNT(col1) as count_alias FROM tbl_name GROUP BY col1 HAVING count_alias > ? | HAVING |
| SELECT * FROM tbl_name1 UNION SELECT * FROM tbl_name2 | UNION |
| SELECT * FROM tbl_name1 UNION ALL SELECT * FROM tbl_name2 | UNION ALL |
| SELECT * FROM ds.tbl_name1 | 包含schema |
| SELECT SUM(DISTINCT col1), SUM(col1) FROM tbl_name | 详见DISTINCT支持情况详细说明 |
| SELECT * FROM tbl_name WHERE to_date(create_time, ‘yyyy-mm-dd’) = ? | 会导致全路由 |
表格数据来源于Sharding-JDBC官方文档:
2.如何对某一模型进行水平分表
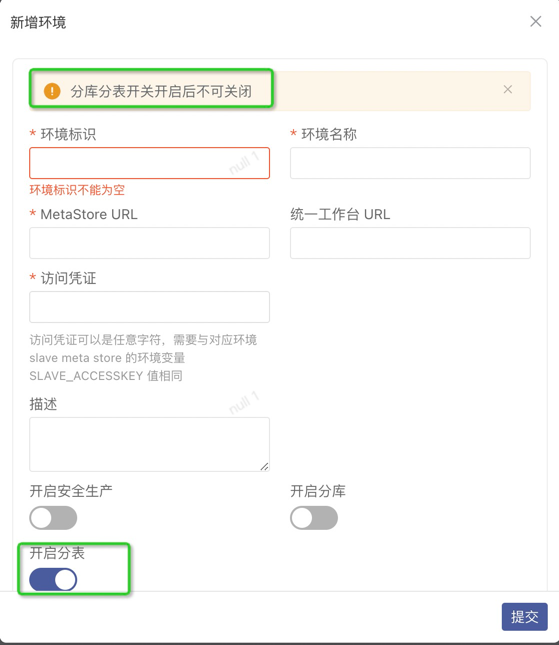
2.1 交付控制台新建环境时开启水平分表功能
2.2 模型上添加注解标注当前模型为分表模型
比如新增了Order模型,Order模型中有字段userId,打算以userId为分表键,
Order模型的@Model注解中添加partition属性,enabled设置为true(默认为false),并设置分表键
@Model( name = "Order", partition = @Partition(enabled = true, field = Order.userId_field))public class Order extends BaseModel<Long> {
@TextMeta(length = 64) @Field(name = "Order title", defaultValue = "") private String orderTitle;
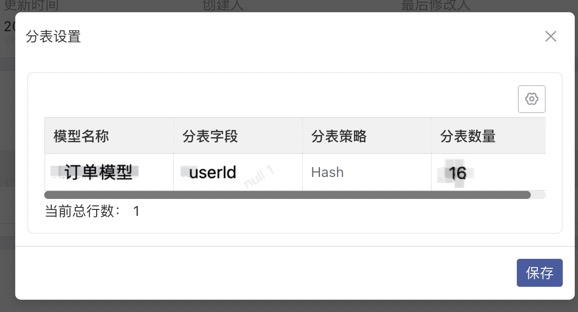
@Field(name = "User id") private String userId;}2.3 模型deploy时设置分表规则,分表数量
如果Order模型分表数量为16,分表策略为简单取模(HASH) 可以在模型上报到交付控制台之后,deploy时,点击右上角分表设置按钮,设置分表规则,分表数量,deploy完成后即完成了Order模型的分表操作。