DS 水平分表用户文档
1.模型开启水平分表后的相关限制
DS内部基于Apache Sharding-JDBC实现,目前DS基于官方版本4.0.0-RC2维护了自己的一个分支,修复了相关bug,增强了相关功能。 Apache Sharding-JDBC官方网站:https://shardingsphere.apache.org/
模型开启水平分表后,相对于单表,存在以下限制:
| 不支持的SQL | 不支持原因 |
|---|---|
| INSERT INTO tbl_name (col1, col2, …) VALUES(1+2, ?, …) | VALUES语句不支持运算表达式 |
| INSERT INTO tbl_name (col1, col2, …) SELECT col1, col2, … FROM tbl_name WHERE col3 = ? | INSERT .. SELECT |
| SELECT COUNT(col1) as count_alias FROM tbl_name GROUP BY col1 HAVING count_alias > ? | HAVING |
| SELECT * FROM tbl_name1 UNION SELECT * FROM tbl_name2 | UNION |
| SELECT * FROM tbl_name1 UNION ALL SELECT * FROM tbl_name2 | UNION ALL |
| SELECT * FROM ds.tbl_name1 | 包含schema |
| SELECT SUM(DISTINCT col1), SUM(col1) FROM tbl_name | 详见DISTINCT支持情况详细说明 |
| SELECT * FROM tbl_name WHERE to_date(create_time, ‘yyyy-mm-dd’) = ? | 会导致全路由 |
表格数据来源于Sharding-JDBC官方文档:
2.如何对某一模型进行水平分表
2.1 交付控制台新建环境时开启水平分表功能
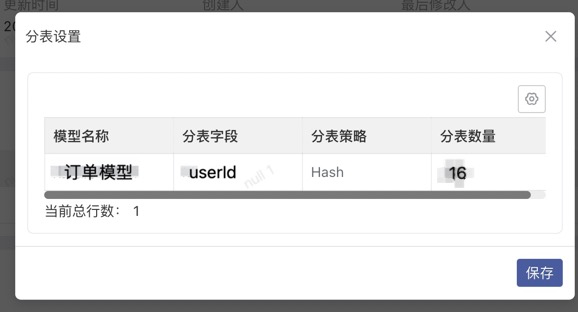
2.2 模型上添加注解标注当前模型为分表模型
比如新增了Order模型,Order模型中有字段userId,打算以userId为分表键,
Order模型的@Model注解中添加partition属性,enabled设置为true(默认为false),并设置分表键
@Model( name = "Order", partition = @Partition(enabled = true, field = Order.userId_field))public class Order extends BaseModel<Long> {
@TextMeta(length = 64) @Field(name = "Order title", defaultValue = "") private String orderTitle;
@Field(name = "User id") private String userId;}2.3 模型deploy时设置分表键,分表规则,分表数量
如果Order模型分表数量为16,分表策略为简单取模(HASH) 可以在模型上报到交付控制台之后,deploy时,点击右上角分表设置按钮,设置分表规则,分表数量,deploy完成后即完成了Order模型的分表操作。
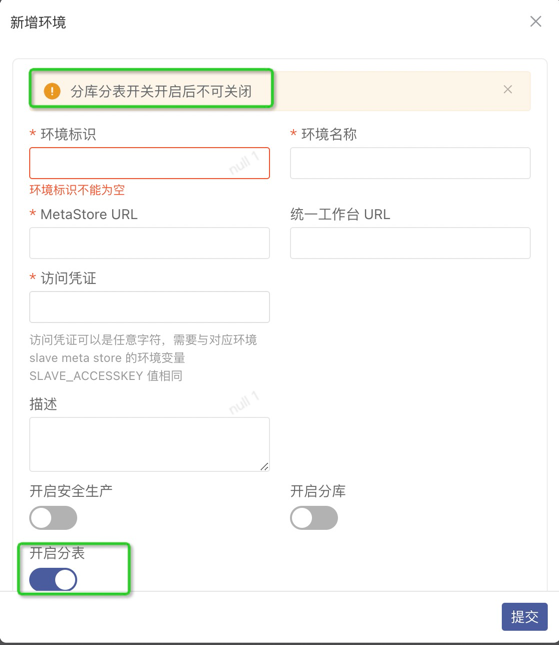
3.支持的分表策略和使用场景
目前DS支持三种分表策略:
- HASH:简单取模
- StrHash:字符串截取
- MM:按月份分表
3.1 HASH简单取模
使用限制
拆分键的数据类型必须是整数类型或字符串类型。
路由方式
如果键值是数字则根据分表键的键值直接按分表数取余。如果键值是字符串,则字符串会先被换算成哈希值再进行路由计算。例如HASH(8)等价于8 % D(D是分表数目), 而HASH(“ABC”)等价于hashcode(“ABC”).abs() % D(D是分表数目)。
应用场景 HASH函数主要应用与如下场景:
- 适合于需要按用户ID或订单ID进行分表的场景。
- 适合于拆分键是字符串类型的场景。
3.2 StrHash
使用限制
拆分键的数据类型必须是字符串类型。
路由方式
StrHash通过指定字符串的开始位置下标与结束下标,以截取拆分键的字符串的某段子串,然后将其作为字符串(或整数)输入进行分表的路由计算,计算具体的物理分片
startIndex:目标子串的开始位置的下标。取值从0开始(即原字符串的第1个字符的下标用0表示)。
endIndex:目标子串的结束位置的下标。取值从0开始(即原字符串的第1个字符的下标用0表示)。
说明 startIndex和endIndex时需注意如下几种取值情况:
当startIndex == j && endIndex = k (j>=0, k>=0 ,k>j)时,表示截取原字符串的[ j, k )区间的字符串作为子串。
例如:
对于字符串ABCDEFG,子串区间[1,5)的值是BCDE。
对于字符串ABCDEFG,,子串区间[2,2)的值是”。
对于字符串ABCDEFG,子串区间[4,100)的值是EFG。
对于字符串 ABCDEFG,子串区间[100,105)的值是”。
如果截取后的键值是数字则根据分表键的键值直接按分表数取余。如果截取后的键值是字符串,则字符串会先被换算成哈希值再进行路由计算。例如HASH(8)等价于8 % D(D是分表数目), 而HASH(“ABC”)等价于hashcode(“ABC”).abs() % D(D是分表数目)。
简单示例:[5,10]:如果[5,10]子串都是数字,则转成数字后取模,否则[5,10]子串.hashCode() 后取模
应用场景
StrHash函数主要应用与如下场景:
-
实现一个分表只对应一个拆分表键的取值(字符串类型)的精准路由效果。 例如,某个互联网金融应用是按订单号分表,该应用的订单号有个特点,就是订单号的最后3位字符串是一个整数,其取值范围是000~999。该应用的需求是要将订单号后3位的每一个数值只单独路由到一个物理分表。那么分表采用拆分函数StrHash,就可以达到效果。
-
典型的点查场景 STR_HASH拆分函数适用于使用字符串类型作为拆分键并且是绝大部分都是点查的场景,如根据ID查交易订单、物流订单等。
3.2 MM 按月份分表
使用限制
拆分键的类型必须是DATETIME
按MM进行分表,由于一年的月份只有12个月,所以分表数量固定为12。
路由方式
根据分表键时间值的月份数进行取余运算并得到分表下标。
使用场景
MM函数适用于按月份数进行分表,分表的表名即为月份数。
3.注意事项
3.1 分表策略,分表键,分表数量无法修改
开始选择Hash,16张,后面想改为Hash,32张,这种场景目前不支持。
如果确实需要这种变更,目前可以通过先删除这个模型然后重新发布的方式,原始数据需要自己dump后重新洗进去,不推荐进行这种操作。